What is an LLM gateway?
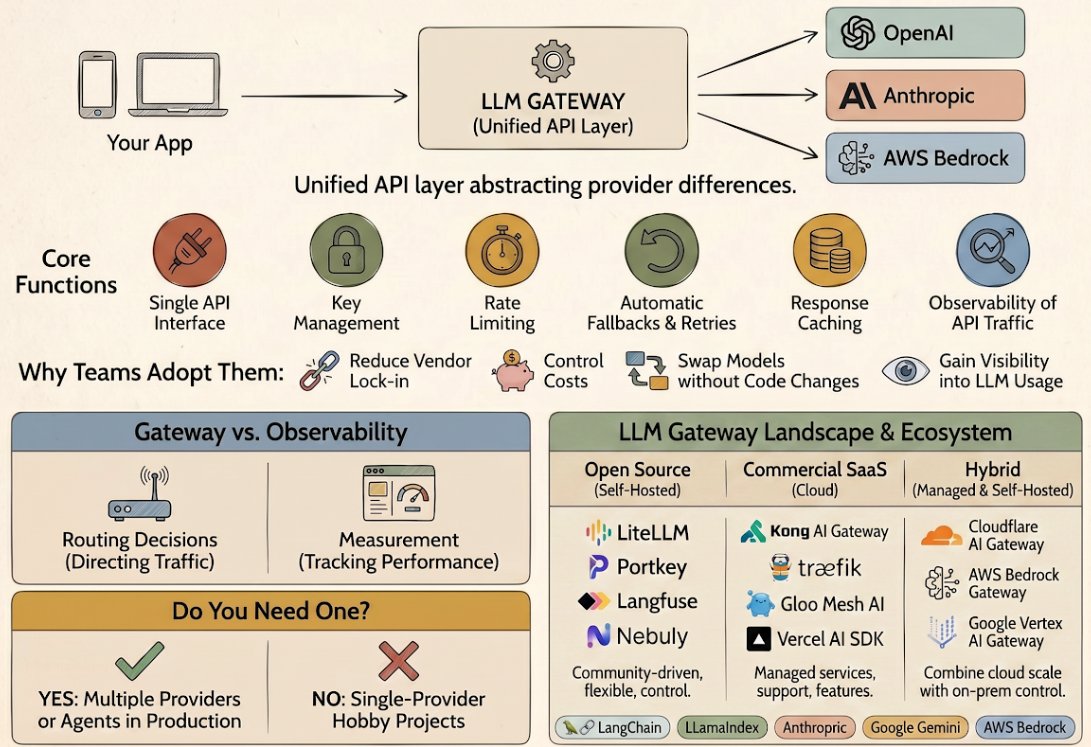
An LLM gateway is a unified API layer that sits between your application and one or more LLM providers, abstracting provider-specific APIs into a single interface and adding cross-cutting concerns like routing, fallbacks, key management, and caching. Instead of writing integration code for OpenAI’s SDK, then Anthropic’s, then AWS Bedrock’s, you write once against a gateway and let it handle the details of talking to each provider.
A gateway acts as a reverse proxy for LLM traffic. It intercepts your requests, enforces policies, applies transformations, routes to the appropriate backend, and logs what happened. Some gateways are thin (basic API translation). Others are thick (guardrails, cost control, agentic features).
Why teams adopt gateways
Provider diversification without integration overhead. Writing per-provider SDKs into production code couples your app to each provider’s API shape. A gateway abstracts that away. You call one interface and can swap providers, or add fallbacks, without touching your application code.
Cost control and transparency. Most production LLM usage surprises teams. A gateway intercepts every request and can log cost, tokens consumed, latency, and error rates in one place. Some gateways support per-user budgets and per-model cost caps with real-time spend tracking. When a cheaper model works as well as an expensive one, you can route to it and measure the impact.
Fallback routing when providers fail. If your primary provider is rate-limited or down, a gateway can automatically retry against a secondary provider. This is critical for production agents where “sorry, OpenAI is having issues” is not an acceptable failure mode.
Model swaps without code changes. A/B testing models, rolling out new ones, or deprecating old ones becomes a configuration change in the gateway instead of a deployment. This matters when you’re optimizing for latency, cost, or quality and need to experiment quickly.
Simpler developer experience. One API. One set of credentials to manage. One place to understand rate limits and retry behavior. Valuable when many developers and services are calling LLMs.
Core capabilities
Most gateways provide a baseline set of features:
- Unified API: an OpenAI-compatible REST API or SDK, so clients don’t have to change when you swap providers.
- Key management: credentials for each provider are stored centrally (encrypted at rest), so your application never sees raw API keys. This reduces credential sprawl and the risk of keys leaking in logs or code.
- Rate limiting and quotas: enforce per-user, per-team, or per-model rate limits and budget caps. When limits are hit, the gateway rejects requests gracefully instead of letting them propagate to the provider and incur charges.
- Automatic fallback and retries: if a request fails, the gateway can retry the same provider, fall back to an alternate provider, or both. Configurable policies let you set retry counts, backoff strategies, and provider precedence.
- Request and response caching: cache identical or semantically similar requests to avoid redundant API calls. Some gateways support semantic caching (caching based on meaning, not exact string match), which saves cost and latency for agents that reuse context.
- Traffic observability: log every request: latency, tokens (input and output), cost, error messages, provider, model used, user or app identifier. This data is what makes debugging, cost allocation, and performance monitoring possible.
The convergence: gateways and observability
The boundary between gateways and observability platforms has blurred. Many gateways now ship observability features. Many observability platforms now offer proxy-like routing. Conceptually they solve different problems.
Gateways make routing decisions. They choose which provider to call. They decide when to retry, and when to fall back. They’re about control: deciding what happens to each request.
Observability measures what happened. It captures latency, tokens, cost, errors, and other metrics. It’s about visibility: understanding the system after the fact.
A concrete example. You deploy a gateway configured to route 80% of requests to Claude Opus and 20% to a cheaper model. The gateway controls the routing (gateways). Your observability platform logs each request and shows you that the cheaper model has a higher error rate and longer latency (observability). Armed with that data, you adjust the split back to 90%/10%.
Helicone is the canonical example of a hybrid: a proxy gateway (with routing and fallback logic) and an observability-first platform (with dashboards, evals, and experiment tracking built in). The two functions remain distinct. Many teams run a lightweight gateway (like LiteLLM) alongside a separate observability tool, or vice versa.
Notable tools
- LiteLLM is an open-source Python SDK and proxy server supporting 100+ providers (OpenAI, Anthropic, Bedrock, Vertex AI, Cohere, and more) via an OpenAI-compatible interface, with built-in cost tracking, guardrails, load balancing, and logging. Highly extensible and widely used in production.
- OpenRouter is a managed gateway exposing 500+ models from 60+ providers through a single OpenAI-compatible API, with intelligent routing based on cost, latency, and availability, plus automatic failover when providers are down or rate-limited. Ideal for teams that want to use many models without managing multiple accounts and keys.
- Vercel AI Gateway is a Vercel-native managed gateway supporting bring-your-own-key (BYOK) authentication with no additional markup, tightly integrated with the Vercel AI SDK and built for fast model iteration in production applications.
- Cloudflare AI Gateway is edge-deployed across Cloudflare’s 330-city network, supporting multiple providers (OpenAI, Anthropic, Hugging Face, Bedrock, and more) with caching, rate limiting, retries, and model fallback. Particularly strong for latency-sensitive workloads due to edge placement.
- Portkey is a managed gateway and production control plane supporting 1,600+ LLMs with enterprise-grade governance (RBAC, SSO, granular budgets), compliance certifications (SOC2, ISO 27001, GDPR, HIPAA), and deployment options (SaaS, hybrid, or air-gapped). Designed for teams with strict security and audit requirements.
- Bifrost is a high-performance open-source gateway written in Go, optimized for low-latency, high-RPS workloads with roughly 40x lower latency than LiteLLM, supporting 15+ providers and offering adaptive load balancing, clustering, and guardrails. Best for teams that prioritize infrastructure performance over feature breadth.
- Helicone is an open-source hybrid observability and gateway platform with a cloud-hosted API and self-hosted options, supporting 100+ providers with zero-markup pricing and built-in evals, experiments, and monitoring dashboards. Strong choice if you want observability and routing in one platform.
- Kong AI Gateway is an enterprise API gateway with dedicated AI connectivity features, supporting LLM, MCP, and A2A routing with usage analytics, provider-agnostic routing, and deployment options (Konnect SaaS or self-hosted Enterprise). Designed for large organizations already using Kong for general API management.
When you need a gateway (and when you don’t)
You probably don’t need one if
- You are building a toy or hobby project that only calls one provider (e.g., a ChatGPT wrapper for personal use).
- You are prototyping and don’t care about observability, fallbacks, or cost tracking yet.
- Your application is so simple that it doesn’t benefit from vendor diversification or cost control.
You almost certainly do need one if
- You are running agents or applications in production, even single-provider, because you want observability and automatic retries.
- You use multiple LLM providers and want a single interface without per-provider integration overhead.
- You need to control costs: budget per user, per team, or globally; route to cheaper models when quality permits; or measure spend by application.
- You want to experiment with models or providers without code changes. Swapping models should be a config update, not a deployment.
- You need automatic fallback routing: if provider A is down or rate-limited, automatically try provider B.
- You are building multi-tenant applications or services where different customers may have different provider preferences or budgets.
If your LLM use is scattered across multiple services and providers, a gateway pays for itself in visibility and operational safety.
Common questions
- Why is my gateway slower than calling the LLM provider directly?
- Three common causes. First, the gateway hop adds network latency: every request now goes through an extra service before reaching the provider. A well-deployed gateway adds single-digit milliseconds. A misconfigured one (deployed in a different region than the provider's endpoint, behind a slow load balancer, or running on undersized hardware) can add 50 to 200ms. Second, retry logic: if your gateway is configured to retry on transient errors, a flaky connection that succeeds on retry will look like the gateway added latency, when really the gateway hid an underlying problem. Third, semantic-cache overhead: a misconfigured cache that runs similarity search on every request can add 20 to 50ms even when nothing is cached. Profile with the gateway disabled and enabled, compare p50/p95/p99 across the same workload. Most 'gateway is slow' complaints turn out to be retries firing on a flaky provider, not the gateway itself.
- Why does my gateway keep falling back when the primary provider works fine?
- Most fallback policies fire on any error, not only on the ones you care about. The usual culprits: rate-limit response headers from the provider that the gateway misreads as failure; transient timeouts because your gateway's timeout is set tighter than the provider's actual p99; 'soft' errors like a malformed completion that the gateway counts as a hard failure. Open the gateway's trace logs and look at which provider got hit, which error fired, and what the policy did with it. Most gateways let you scope fallback policies to specific error codes (5xx and rate-limit responses, but not 4xx auth/validation errors). If the same fallback fires for thousands of requests in a row, it's almost always a misconfigured policy rather than a real provider outage.
- Do I need a gateway if I'm only using one provider?
- Not strictly. If you use OpenAI exclusively and don't care about observability or fallbacks, calling their SDK directly is simpler. Even single-provider deployments benefit from a lightweight gateway for rate limiting, cost tracking, and automatic retries. Many teams find that a thin gateway (like LiteLLM in passthrough mode) adds minimal overhead and meaningful resilience.
- How much latency does a gateway add?
- It depends. A well-designed gateway adds single-digit milliseconds (Bifrost claims under 100 microseconds of overhead). A poorly designed one can add hundreds of milliseconds. If latency-sensitive workloads matter, benchmark the specific gateway and configuration in your environment. Edge-deployed gateways like Cloudflare's can reduce latency by sitting closer to users.
- Can I self-host a gateway?
- Yes. LiteLLM, Helicone, Bifrost, and Kong are all open-source and self-hostable. Vercel and Portkey offer managed services that also support self-hosted or hybrid deployment. Self-hosting trades operational overhead (you run the infrastructure and handle upgrades) for control and privacy. Many teams start with a managed gateway and self-host later.
- What's the difference between a gateway and an API management platform?
- API management platforms (Kong, Apigee, AWS API Gateway) are general-purpose tools for managing HTTP API traffic: RESTful services, webhooks, microservices, and the rest. They can be used as gateways for LLM traffic. They aren't LLM-specific. LLM gateways are purpose-built to handle things like model routing, token accounting, provider-specific quirks, and cost tracking. Many teams use an API management platform for general infrastructure and a specialized LLM gateway for LLM traffic.
Further reading
- LiteLLM GitHub. Source for the most widely deployed open-source gateway.
- LiteLLM Docs. Configuration and deployment guides.
- OpenRouter Docs. Model catalog and routing configuration.
- Vercel AI Gateway. Integration with the Vercel AI SDK.
- Cloudflare AI Gateway Docs. Edge deployment and multi-provider setup.
- Portkey AI Gateway. Enterprise features and deployment models.
- Bifrost Documentation. Performance benchmarks and Go-based architecture.
- Helicone GitHub. Source for the observability-focused hybrid platform.
- Kong AI Gateway. Enterprise API management for AI connectivity.
See also: What is agent observability?. What is agent token economics (forthcoming).